
Overview
This blog post demystifies enterprise AI deployment by exploring how organizations can move from experimental models to production-grade systems. It begins by defining AI as a strategic enabler, then explains how modern AI applications integrate data interpretation, reasoning, and interaction. The core focus is on building trustworthy systems via transformer models, semantic embeddings, vector search databases, and retrieval-augmented generation (RAG). These components ensure AI outputs are explainable, contextually relevant, and grounded in real-world data. The post concludes by highlighting the importance of foundational architecture and offering a preview of deeper dives into each AI layer in future installments.
What Is AI – And Why Should You Care?
Artificial Intelligence (AI) is no longer a future ambition—it is a present imperative. Defined simply, AI is the science of building machines and systems that can learn, reason, and act. From natural language interfaces and predictive analytics to autonomous decision systems, AI enables organizations to unlock value from data at a speed and scale that human processes alone cannot match.
But for enterprise leaders, AI is more than technology—it’s strategy. It determines whether your organization will lead with insight or lag in inefficiency. The question isn’t whether to adopt AI, but how to do so safely, effectively, and with measurable outcomes.
For customers the concern isn’t the novelty of AI. It’s trust, performance, alignment, and governance. You care because AI that isn’t explainable, grounded, or deployable at scale introduces risk. AI done right, however, delivers unmatched operational leverage: faster decisions, smarter systems, and better service.
What Is an AI Application?
An AI application is more than a chatbot or a classifier. It is a system that ingests real-world data, interprets it through machine-learned models, and generates outputs aligned to a mission—whether that’s identifying fraud, prioritizing disaster relief, or optimizing logistics.
Modern AI applications often blend multiple capabilities:
- Perception (e.g., NLP, computer vision)
- Retrieval and reasoning (e.g., RAG pipelines, semantic search)
- Decision support (e.g., recommendations, scoring
- Interaction (e.g., GenAI copilots, assistants)
And the most powerful of them are semantic—they understand not just what data says, but what it means in context.
In enterprise settings, this means aligning AI with your domain language, policy rules, regulatory constraints, and operational goals. An AI application is not magic. It’s architecture. One built intentionally to serve your needs.
How Do You Deploy an AI Application?
The real challenge isn’t building AI—it’s deploying it. Moving from a model demo to a production-grade AI system requires a unified stack that handles:
- Data Ingestion: Structured (databases, APIs) and unstructured (PDFs, logs, transcripts).
- Semantic Encoding: Embeddings that reflect real-world meaning, not just statistical proximity.
- Vector Search + Graphs: Retrieval infrastructure that surfaces context-aware facts—not just keywords.
- Model Selection: Open-source, closed, or fine-tuned LLMs matched to your domain and governance needs.
- Generation & Reasoning: RAG pipelines or rules-based augmentation to ground model outputs.
- Human-in-the-Loop: Workflow integration for validation, compliance, and continual improvement.
- Interface Layer: Dashboards, APIs, and copilots that deliver AI where the mission happens.
Deployed correctly, an AI application becomes a trusted partner—not a black box. It learns from your data, aligns to your rules, and supports your experts.
Laying the Foundation: From Raw Inputs to Structured Meaning
Before AI can generate insights, make decisions, or respond intelligently, it must first understand what it’s seeing. That understanding starts with data.
Across the enterprise, data comes in many forms: structured tables from ERPs, semi-structured APIs, unstructured PDFs, sensor streams, emails, chats, and more. For AI to process this information, it must first be ingested—collected, normalized, and routed into a usable pipeline.
This phase, known as data ingestion, forms the bottom layer of any enterprise AI stack. Robust ingestion systems handle:
- Batch and real-time inputs from multiple modalities
- Parsing and preprocessing, like text extraction or schema mapping
- Metadata tagging and routing for downstream systems
But ingestion alone is not enough. Raw data must be translated into a format AI models can reason over.
Understanding Meaning: The Role of Transformer Models
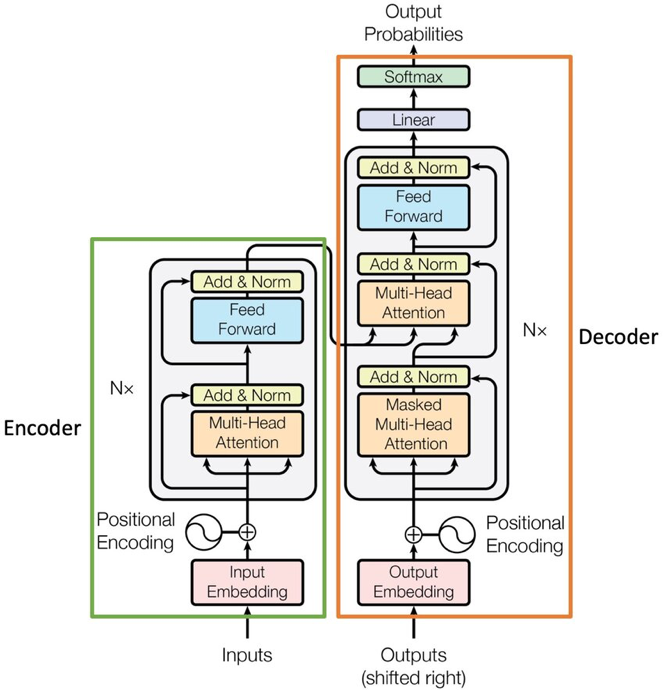
Once enterprise data is ingested and structured, the next challenge is helping AI interpret its meaning. This is where Transformer models come in. Introduced in 2017, Transformers are now the foundation of most modern AI systems, including large language models (LLMs) like GPT and Claude.
The Transformer architecture is a structured pipeline that processes input data through multiple layers of contextual analysis to produce task-specific outputs. It is designed to handle complex sequence tasks such as language translation, summarization, and text generation.
Transformers analyze sequences (like sentences or token streams) using a mechanism called self-attention, which allows them to evaluate relationships between all parts of an input, regardless of order or distance. This enables deep contextual understanding.
Transformer is composed of two key components:
- Theencoder, which converts raw input into semantic vector embeddings
- Thedecoder, which generates outputs based on the encoder’s representation and prior outputs
These encoder-decoder layers are stacked to form the core of an LLM. The output of the encoder feeds directly into semantic encoding, powering the next steps of retrieval, reasoning, and generation.
Adapted from Wan, Z., Xu, C., & Suominen, H. (2021). Enhancing Clinical Information Extraction with Transferred Contextual Embeddings. arXiv:2109.07243.
Available via ResearchGate.
Licensed under CC BY-SA 4.0. No changes were made.
Embedding Meaning: The Role of Semantic Encoding
Vector embedding is a fixed-length vector v ∈R^d that captures the semantic characteristics of some input data, such as a sentence, product, image, or event log. These embeddings are often generated by the encoder component of a Transformer model. By using self-attention to understand contextual relationships between input elements, the encoder produces high-dimensional representations that capture semantic meaning, making them ideal inputs for downstream AI tasks.
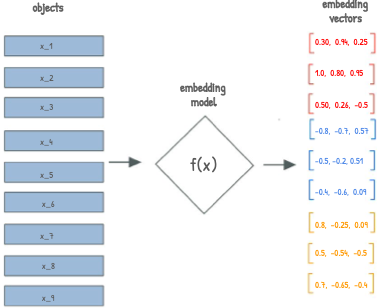
Given an input x, we apply a trained function:
f(x)=v, where f∶X→ R^d
The function f is typically a deep neural network (DNN) — a parameterized function composed of many layers of linear algebra and non-linear activation functions. In mathematical terms, a DNN applies a series of transformations:
f(x)= f_n (f_(n-1) (…f_1 (x)))
Each layer maps input features into a latent representation, progressively learning more abstract features. These networks are trained via backpropagation using massive datasets and gradient descent to minimize a loss function that encourages semantically similar inputs to produce nearby vectors.
Closeness in this space is measured using distance metrics, such as cosine similarity or Euclidean distance, which quantify the degree of semantic alignment between two vectors. This makes it possible to power systems like semantic search and recommendation engines, retrieving results that are meaningfully related, even if they don’t share exact keywords.
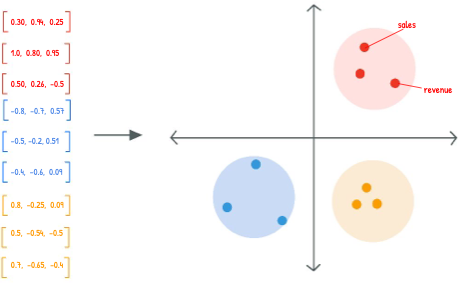
For instance, in a well-trained embedding space:
- In text, the network learns that “revenue” and “sales” often occur in similar contexts.
- In images, the network learns that objects like “car” and “truck” share low-level visual structure.
This structure enables embedding models to generalize and operate across domains in a way that reflects meaning, not just surface similarity.
Vector Database: Infrastructure for Semantic Search and Generation
A vector database stores and searches data as embeddings, allowing AI systems to find information based on meaning instead of exact matches.
Once data is transformed into vector embeddings, it needs to be stored, indexed, and made retrievable in a way that preserves its semantic meaning. That’s where vector databases come in.
A vector database organizes and searches data by embedding similarity, allowing AI systems to retrieve content based on meaning rather than exact keyword matches. This capability is foundational for powering tasks like semantic search, retrieval-augmented generation (RAG), and context-aware recommendations.
Unlike traditional scalar databases that match structured fields (e.g., price, ID, category), vector databases work with high-dimensional embeddings that reflect deeper relationships between concepts. These embeddings are typically produced by the Transformer’s encoder, which compresses input data into dense vectors that preserve semantic relationships across a wide range of contexts. This shift allows AI to reason over language, images, and behaviors with contextual understanding.
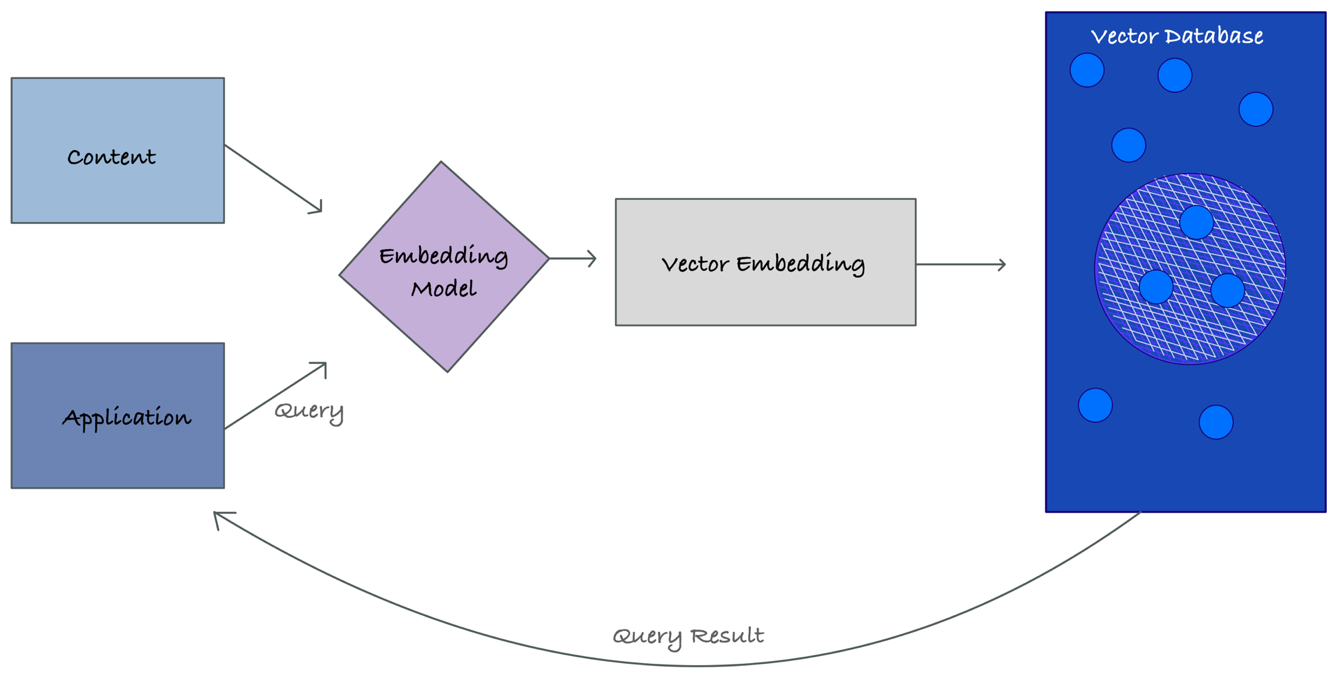
- An embedding model transforms content (like documents or files) into vector embeddings: numerical representations of meaning.
- These embeddings are stored in a vector database; each is linked to the original content from which they were generated.
- When an application sends a query, it’s also converted into a vector embedding using the same model.
- The vector database performs a similarity search, finding embeddings that are semantically closest to the query.
- The matched embeddings and their associated content are returned as results to the application.
This retrieval process lays the foundation for the next step: vector decoding—the act of turning those abstract embeddings back into meaningful, usable information.
From Embeddings to Insight: The Role of Vector Decoding
While embedding models translate inputs into high-dimensional vectors that encode semantic meaning, vector embeddings are not the end of the process—they are the beginning of interaction. Vector decoding refers to the retrieval and interpretation of these embeddings, allowing systems to turn latent representations back into structured or interpretable outputs.
What Is Vector Decoding?
Vector decoding is not the mathematical inversion of an embedding. Instead, it is the retrieval of associated real-world data linked to a stored vector in a vector database. Each embedding is typically indexed alongside metadata, an identifier, or an object pointer—enabling decoded results to return context-rich documents, chunks, or structured objects.
Why It Matters
How decoding bridges the gap between representation and usability. Once embeddings are queried, systems must return:
- The original passage, record, or asset that generated the vector
- Any associated metadata, such as source, timestamp, or access control
Optional post-processing, like chunk re-ranking or summarization, tailored to the current use case
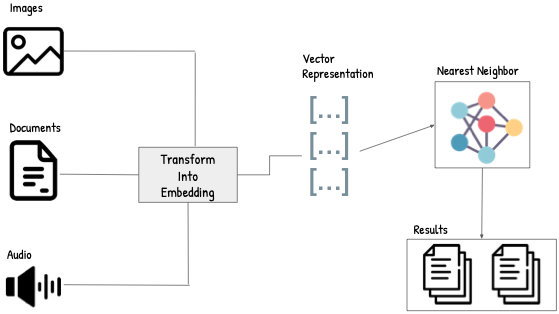
For example, given a query about a legal policy, a retrieval pipeline might:
- Embed the query using the same model used at indexing time
- Search the vector space using approximate nearest neighbor (ANN) techniques
- Decode the results by returning the corresponding policy snippets, filtered by jurisdiction and time range
This decoded content then serves as direct input to a generation model or downstream logic, grounding outputs in concrete, traceable information.
Grounding Language Models: Retrieval- Augmented Generation (Rag)
Once your enterprise data is embedded and indexed in vector space, the question becomes: how do you put it to work inside a language model?
That’s where Retrieval-Augmented Generation (RAG) enters the stack.
While large language models (LLMs) like GPT or Claude can generate fluent, human-like responses, they suffer from a fundamental constraint: they don’t have access to your organization’s data. Their knowledge is frozen at the time of training and based on public corpora.
RAG solves this.
Instead of relying solely on static model weights, RAG injects real-time, relevant data directly into the LLM’s prompt.
How Rag Works
RAG consists of two distinct but coordinated components:
- Retriever: Given a user query, it searches a vector database to return the top K semantically similar documents or snippets.
- Generator: It receives both the original query and the retrieved results as a context-augmented prompt. The LLM then decodes this enriched input into a coherent, grounded response.
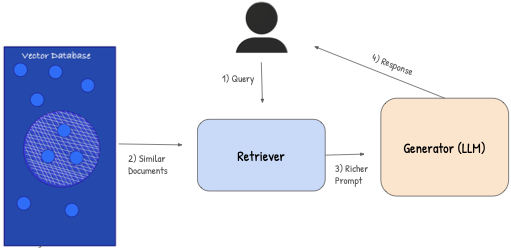
- User Submits a Query
A person asks a question or makes a request — this is passed to the system. - Retriever Finds Relevant Documents
The query is converted into a vector and sent to the Retriever, which searches a vector database for semantically similar content (called “K most similar documents”). - Generator Receives a Richer Prompt
The retrieved documents are combined with the original query and passed to the Generator (the LLM), forming a context-rich input. - LLM Returns a Grounded Response
The LLM uses the retrieved knowledge to generate a more accurate and relevant response, which is returned to the user.
RAG doesn’t require retraining the model, making it flexible and cost-effective. Instead of teaching the model everything, you simply give it access to the right information at the right time.
RAG extends the Transformer architecture by pairing the encoder’s ability to represent semantic meaning with externally retrieved knowledge, which is then passed into the decoder. The decoder doesn’t generate text in isolation—it now synthesizes retrieved content with the original query, producing responses that are grounded, context-rich, and aligned to real-world data. This dynamic flow from retrieval to generation brings LLMs closer to trusted enterprise decision-making.
Closing Thoughts and What’s Next
This paper laid the foundation for understanding how to confidently deploy enterprise AI systems—from ingestion to generation, from raw data to actionable insight. But this is only the beginning.
To fully realize the promise of AI, organizations need more than inspiration—they need a practical, structured approach that guides them through each layer of the AI stack.
Over the next installments, we will break down each core component of enterprise AI architecture in greater detail, including:
- Data Ingestion at Scale: Managing structured, semi-structured, and unstructured data
- Semantic Encoding: Training and tuning domain-specific embedding models
- Vector Infrastructure: Architecting for semantic search and retrieval performance
- Retrieval-Augmented Generation (RAG): Designing trustworthy generation pipelines
- Human-in-the-Loop Systems: Integrating governance, validation, and feedback
- Interface Design: Delivering AI through dashboards, copilots, and mission workflows
Each paper will include actionable insights, implementation strategies, and real-world examples to help technical and business leaders navigate the AI deployment journey.